Key Collector is one of the main SEO tools. This program, created for the selection of the semantic core, is included in the category of must-have tools for promotion. It is as important as a scalpel to a surgeon or a steering wheel to a pilot. After all, it is unthinkable without keywords.
In this article, we will look at what Kay Collector is and how to work with it.
What is Key Collector for
Then go to the settings (the gear button in the panel in the upper left corner of the program window) and find the tab “ Yandex.Direct«.
Click on the " Add as a list»And enter the created accounts in the format Login: Password.
Attention! add @ yandex.ru after login not necessary!
After all the operations, you get something like the following:
But that's not all. Now you need to create a Google AdWords account, which will be linked to this Google account. Without an account in AdWords, it will be impossible to get data on keywords, since they are taken from there. When creating your account, select your language, time zone, and currency. Please note that this data will not be possiblechange.
After creating your AdWords account, reopen the Key Collector settings and the " Google.AdWords". It is recommended to use only one Google account in the settings here.
Anti-captcha
This item is optional, but I still recommend using anti-captcha. Of course, if you like to enter captcha manually every time, it's up to you. But if you do not want to waste your time on this, find the "AntiCaptcha" tab in the settings, enable the "Antigate" radio button (or any other of the proposed options) and in the field that appears, enter your anticaptcha key. If you don't have a key yet, create one.
Captcha recognition is a paid service, but $ 10 is enough for at least a month. In addition, if you do not scrape search engines every day, this amount will be enough for a year.
Proxy
By default, the program uses your primary IP address for parsing. If you often do not need to use the Key Collector, you can forget about the proxy settings. But if you often work with the program, search engines can often slip you a captcha and even temporarily ban your IP. In addition, all users who access the Network under a shared IP will suffer. This problem occurs, for example, in offices.
Also, users from Ukraine may experience difficulties in parsing Yandex from the main IP.
Finding free proxies that are still not in the search engines' bath can be quite difficult. If you have a list of such addresses, enter them in the settings in the " Network". Then click on the " Add line«.
Another option is to create a file with addresses in the format IP: port, copy them to the clipboard and add them to the collector using the button “ Add from clipboard«.
But I recommend using hidemy.name's paid VPN. In this case, an application is installed on the computer that enables / disables VPN on demand. In this application, you can also change the proxy itself and its country. You don't have to configure anything additionally. Just turn on the VPN and work comfortably with the Collector.
I have listed the basic settings that are needed to get started. I advise you to go through all the tabs yourself and study the program settings. Maybe you will find the items in the settings that are right for you.
Finding keywords with Key Collector
Finally, we have reached the actual selection of the semantic core. In the main window of the program, click on the large button " New project". I advise you to name the project file by the name of the site, for example, site.ru, and save it to a specially created folder for Key Collector projects, so that you do not waste time on searches later.
The Collector is convenient for sorting keywords into groups. It is convenient for me when the hierarchy of groups in the project corresponds to the future, so the first group (the default group) for me corresponds to the main page of the site.
For example, let's work with the topic “Moscow website development”. Let's start with Yandex.
First you need to set the region:
Now you need to open " Batch collection of words from the left column of Yandex.Wordstat»And in the window that appears, enter the 5 most obvious key phrases in this topic (on their basis, parsing will be performed).
Now you need to click on the " Start collecting«.
That's it, you can go make coffee or switch to other tasks. Kay Collector will take some time to parse the key phrases.
As a result, something like the following will be displayed:
Stop words
Now you need to filter out words and phrases that are not suitable at the moment. For example, the combination of the words "website development moscow is free»Will not work, since we do not provide free services. It is extremely exciting to search for such phrases manually in the semantic core for hundreds and thousands of requests, but it is still better to use a special tool.
Then you need to click on the plus sign:
You've probably noticed that the program has a large number of different options when working with keywords. I am explaining the basic, simplest operations in Key Collector.
Dealing with the frequency of requests
After filtering by negative keywords, you can start parsing by frequency.
Now we see only the speaker with the overall frequency. To get the exact frequency for each keyword, you need to enter it in Wordstat in the quotation mark operator - "keyword".
In the Collector, this is done as follows:
If necessary, you can collect the frequency with the operator "! Word".
Then you need to sort the list by frequency "" and remove words with a frequency of less than 10 (sometimes 20-30).
Second way to collect frequency (slower):
If you know for sure that you are not interested in the frequency below a certain value, you can set the threshold in the program settings. In this case, phrases with a frequency below the threshold will not be included in the list at all. But you can miss promising phrases this way, so I do not use this setting and do not recommend it to you. However, proceed as you see fit.
As a result, a semantic core, more or less suitable for subsequent work, is obtained:
Please note that this semantic core is just an example, created only to demonstrate how the program works. It is not suitable for a real project, as it is poorly developed.
Right column Yandex.Wordstat
Sometimes it makes sense to parse the right column of Wordstat (queries similar to "your query"). To do this, click on the appropriate button:
Google and Key Collector
Queries from Google statistics are parsed by analogy with Yandex. If you have created a Google account and an AdWords account (as we remember, just a Google account is not enough), click on the corresponding button:
In the window that opens, enter the queries of interest and start the selection. Everything is similar to parsing Wordstat. If necessary, in the same window, specify additional settings specifically for Google (when you click on the question icon, help will appear).
As a result, you will receive the following data for AdWords:
And you can continue working with semantics.
conclusions
We have analyzed the basic settings of the Key Collector (something without which it is impossible to start working). We also looked at the simplest (and basic) examples of using the program. And we picked up a simple semantic core using statistics from Yandex.Wordstat and Google AdWords.
As you can imagine, the article shows approximately 20% of all program features. To master the Key Collector, you need to spend a few hours and study the official manual. But it's worth it.
If after this article you decide that it is easier to order a semantic core from specialists than to figure it out yourself, write to me through the page, and we will discuss the details.
And a bonus video: a dude named Derek Brown plays the saxophone masterly. I even attended his concert during the jazz festival, which is really cool.
I started writing this article quite a long time ago, but just before the publication it turned out that my colleagues in the profession were ahead of me and posted almost identical material.
At first, I decided that I would not publish my article, since the topic was already well covered by more experienced colleagues. Mikhail Shakin spoke about 9 ways to clean up requests in KC, and Igor Bakalov filmed a video about implicit duplicate analysis... However, after some time, after weighing all the pros and cons, I came to the conclusion that perhaps my article has the right to life and may be useful to someone - do not judge strictly.
If you need to filter a large keyword base of 200k or 2 million queries, then this article can help you. If you work with small semantic kernels, then most likely the article will not be particularly useful for you.
We will consider filtering a large semantic core using the example of a sample consisting of 1 million queries on a legal topic.
What do we need?
- Key Collector (hereinafter KC)
- At least 8GB of RAM (otherwise we will have hellish brakes, spoiled mood, hatred, anger and rivers of blood in the eye capillaries)
- Common Stop Words
- Basic knowledge of the regular expression language
If you are completely new to this business and are not best friends with KC, then I strongly recommend that you familiarize yourself with the internal functionality described on the official pages of the site. Many questions will disappear by themselves, and you will also understand a little in the regular season.
So, we have a large database of keys that need to be filtered. You can get the base through self-parsing, as well as from various sources, but today is not about that.
Everything that will be described below is relevant for the example of one specific niche and is not an axiom! In other niches, some of the actions and stages may differ significantly.! I do not pretend to be a Guru semantics, but only share my thoughts, developments and considerations on this score.
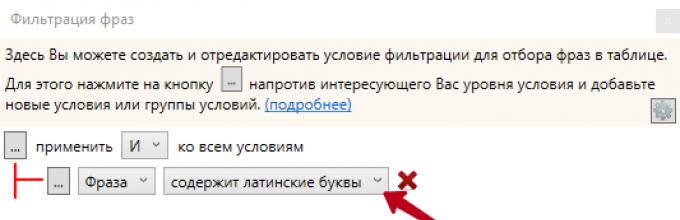
Step 1. Remove Latin characters
Delete all phrases containing Latin characters. As a rule, such phrases have an insignificant frequency (if any) and they are either erroneous or irrelevant.
All manipulations with selections for phrases are done through this cherished button.

If you took the millionth nucleus and reached this step, then the eye capillaries can begin to burst here, because on weak computers / laptops, any manipulations with a large SN can, should and will shamelessly slow down.
Select / mark all phrases and delete.
Step 2. Remove specials. Symbols
The operation is similar to the removal of Latin characters (you can carry out both at the same time), however, I recommend doing everything in stages and viewing the results with your eyes, and not "cutting off the shoulder", because sometimes even in a niche that you seem to know everything about, there are delicious queries that can fall under the filter and which you might simply not know about.

A little advice, if you have a lot of good phrases in your sample, but with a comma or other symbol, just add this symbol to the exceptions and that's it.
Another option (samurai path)
- Download all the necessary phrases with special characters
- Delete them in KC
- In any text editor, replace the given character with a space
- Load back.
Now the phrases are clean, their reputation has been bleached and the sample is based on specials. symbols will not affect them.
Step 3. Remove repetitions of words
And again we will use the functionality built into KC by applying the rule
There is nothing to add here - everything is simple. We kill garbage without a grain of doubt.
If you are faced with the task of performing strict filtering and removing as much garbage as possible, while sacrificing some share of good queries, then you can combine all 3 first steps into one.
It will look like this:

IMPORTANT: Don't forget to switch "AND" to "OR"!
Step 4. Delete phrases consisting of 1 and 7+ words
Someone may object and talk about the coolness of odd words, no question - leave it, but in most cases, manual filtering of odnoslovniks takes a very long time, as a rule, the ratio of good / bad odnoslovony is 1/20, not in our favor. Yes, and drive them into the TOP using the methods for which I collect such cores from the category of science fiction. Therefore, creaking with a heart, we send words to the forefathers.

I anticipate the question of many, "why delete long phrases?" My answer is that phrases consisting of 7 or more words for the most part have a spam structure, do not have a frequency and in the general mass form a lot of duplicates, it is thematic duplicates. I will give an example to make it clearer.

In addition, the frequency of such questions is so small that often space on the server is more expensive than the exhaust from such requests. In addition, if you browse the TOPs for long phrases, then you will not find direct occurrences either in the text or in the tags, so the use of such long phrases in our syllabus does not make sense.
Step 5. Cleaning up implicit takes
We pre-configure the cleaning, complementing it with our own phrases, indicating a link to my list, if there is anything to supplement with - write, we will strive for perfection together.

If you do not do this, and use the list, kindly provided and hammered into the program by the creators of KC by default, then such results will remain in the list, and these are, in fact, very duplicates.

We can perform smart grouping, but in order for it to work correctly, it is necessary to remove the frequency. And this, in our case, is not an option. Because To remove frequency from 1 mln. keev, but even if from 100k - you will need a pack of private proxies, anti-captcha and a lot of time. Because even 20 proxies will not be enough - after an hour the captcha will start to pop up, whatever one may say. And this business will take a lot of time, by the way, the budget of the anti-captcha will also eat up pretty much. And why even remove the frequency from junk phrases that can be filtered out without much effort?
If you still want to filter phrases with smart grouping, removing frequencies and gradually removing garbage, then I will not describe the process in detail - see the video that I referred to at the very beginning of the article.
Here are my cleanup settings and the sequence of steps

Step 6. Filter by stop words
In my opinion, this is the most dreary point, drink tea, smoke a cigarette (this is not an appeal, it is better to quit smoking and gobble up a cookie) and with fresh energy sit down to filter the semantic core by stop words.
Don't reinvent the wheel and start building stopword lists from scratch. There are ready-made solutions. In particular, here's to you, as a basis more than will go.
I advise you to copy the plate into the feed of your own PC, or what if the Shestakov brothers decide to leave “your charm” to themselves and close access to the file? As the saying goes, "If you are paranoid, it does not mean that you are not being followed ..."
Personally, I ungrouped stop words into separate files for certain tasks, see the example in the screenshot.

The file "General list" contains all stop words at once. In the Key Collector, open the stop-word interface and load the list from the file.

I put just a partial occurrence and a tick in the box "Search matches only at the beginning of words." These settings are especially relevant with a huge amount of stop words, for the reason that many words consist of 3-4 characters. And if you set other settings, then you may well filter out a lot of useful and necessary words.
If we do not tick the above box, then the vulgar stop word "fuck" will be found in such phrases as "advice to state insurance", "how to insure deposits", etc. etc. Here is another example, on the stop word "rb" (Republic of Belarus) a huge number of phrases will be marked, such as "compensation for damage consultation", "filing a claim in the arbitration process", etc. etc.
In other words - we need the program to select only phrases where stop words occur at the beginning of words. The wording hurts the ear, but you can't erase the words from the song.
Separately, I note that this setting leads to a significant increase in the time for checking stop words. With a large list, the process can take 10 and 40 minutes, and all because of this checkbox, which increases the search time for hundred words in phrases ten or even more times. However, this is the most adequate filtering option when working with a large semantic core.
After we have gone through the basic list, I recommend that you see with your eyes whether any necessary phrases have fallen under the distribution, and I am sure that it will be so, tk. general lists of basic stop words are not universal and have to be worked out separately for each niche. This is where “dancing with a tambourine” begins.
We leave only the selected stop words in the working window, it is done like this.

Then we click on the "analysis of groups", select the mode "by separate words" and see what is superfluous in our list due to inappropriate stop words.

Remove the inappropriate stop words and repeat the cycle. Thus, after a while we will "sharpen" a universal public list for our needs. But that is not all.
Now we need to find stop words that are found specifically in our database. When it comes to huge databases of keywords, there is always some kind of "branded rubbish", as I call it. Moreover, this can be a completely unexpected set of delirium and you have to get rid of it on an individual basis.
In order to solve this problem, we will again resort to the Group Analysis functionality, but this time we will go through all the phrases remaining in the database after the previous manipulations. We will sort by the number of phrases and with eyes, yes, yes, yes, with pens and eyes, we will look through all phrases, up to 30-50 in a group. I mean the second column "number of phrases in the group."
I will hasten to warn the faint of heart, the seemingly endless scroll bar "will not make you spend a week filtering, scroll it by 10% and you will already reach groups that contain no more than 30 requests, and such filtering should be done only by those who know a lot in perversions.
Right from the same window, we can add all the garbage to the word stop (the shield icon to the left of the selectbox).

Instead of adding all these stop words (and there are many more, I just didn't want to add a vertical long screenshot), we gracefully add a filter root and cut off all variations at once. As a result, our stop-word lists will not grow to enormous sizes and, most importantly, we we will not waste extra time looking for them... And at large volumes, this is very important.
Step 7. Remove 1 and 2 symbolic "words"
I can’t find an exact definition for this type of combination of symbols, so I called it “words”. Perhaps someone who has read the article will tell you which term is better, and I will replace it. Here I am so tongue-tied.
Many will ask, "why do this at all?" The answer is simple, very often such arrays of keywords contain garbage of the type:

A common feature of such phrases is 1 or 2 characters that do not make any sense (in the screenshot, an example with 1 character). This is what we are going to filter. There are pitfalls here, but first things first.
How to remove all 2-character words?
To do this, we use the regular

Bonus tip: Always keep the regular patterns! They are not saved within the project, but within KC in general... So they will always be at hand.
(^ | \ s +) (..) (\ s + | $) or (^ | \ s) (1,2) (\ s | $)
(st | fz | uk | na | rf | li | by | st | not | un | to | from | for | to | from | about)
Here is my version, customize to fit your needs.
The second line contains exceptions, if you do not enter them, then all phrases containing combinations of characters from the second line of the formula will be included in the list of candidates for deletion.
The third line excludes phrases that end with "рф", because these are often normal useful phrases.
Separately, I want to clarify that the option (^ | \ s +) (..) (\ s + | $) will select everything - including numerical values... Whereas the regular (^ | \ s) (1,2) (\ s | $) - will affect only alphabetic ones, special thanks to Igor Bakalov for it.
We apply our design and remove junk phrases.
How to remove all 1 character words?
Everything here is somewhat more interesting and not so unambiguous.
At first I tried to apply and modernize the previous version, but as a result I didn’t manage to clean out all the garbage, nevertheless - this scheme will suit many people, try it.

(^ | \ s +) (.) (\ s + | $)
(s | v | u | i | k | y | o)
Traditionally, the first line is the regex itself, the second is an exception, the third one excludes those phrases in which the listed characters occur at the beginning of the phrase. Well, it is logical, because there is no space in front of them, therefore, the second line does not exclude their presence in the sample.
And here is the second option with which I delete all phrases with one-character garbage, simple and merciless, which in my case helped to get rid of a very large amount of left-handed phrases.

(y | ts | e | n | g | w | w | z | x | b | f | s | a | p | r | l | d | w | e | h | m | t | b | b | y )
I excluded from the sample all phrases where “Moscow” occurs, because there were a lot of phrases of the type:

and I need it you yourself guess why.
Key Collector is one of the most popular programs for collecting the semantic core (we wrote about what it is in the article "The role of key queries in website promotion"). With it, you will find all the key queries for your site in half an hour. And then you can start promoting: order content from copywriters or set up contextual advertising.
Key Collector is intended for professionals, so its interface is rather complex and unfriendly. Too many buttons and settings. But don't worry, now we will help you figure it out.
Step 1. Installation
Key Collector is a paid service, it costs 1,700 rubles. There is no subscription fee - you buy the program once and for all.
First, you need to install the program. It only works on Windows OS, there is no Mac OS version. What is needed for this?
- 1. Download Key Collector → key-collector.ru/buy.php. Don't close the page, you still need it.
- 2. Run the downloaded file and follow the instructions of the installation wizard.
- 3. When the installation is complete, run the program itself and copy the code - HID.

- 4. Fill out the application form on the website and insert your HID into it.

It is important to indicate only name, email, HID and payment method
- 5. Click "Submit Application". The Key Collector staff will send you an email with detailed instructions on what to do next.
Now all that remains is to pay for the service - and you will be sent an activation key. Download it and provide the program with the path to the key file.

That's it, Key Collector is activated and ready to go.
Step 2. Setting
* There are many functions in Key Collector, but for now we will only talk about the main ones.
The program is already ready to work - you can build a semantic core with basic settings. The only thing you need to do before starting work is to indicate your Yandex account. It is needed for work.
Important: do not include your main account. If something goes wrong, he can be blocked.
For this:
- 1. First, create a separate account specifically for the Key Collector. This can be done here → yandex.ru/registration.
- 2. Now run the program. Click File → Preferences.

- 3. Open the section "Parsing" → "Yandex.Direct". Click in the empty field under "Yandex Login".

- 4. Here you need to write your username. If you don’t remember it, this is the part of the email address that goes before @. Enter your password in the Yandex Password field.

- 5. Now you need to check your account and activate it. Click on the green "Run" button in the same window.

Verification will take about 10-20 seconds
- 6. When the check is over, you can start working.
Close the settings - we begin to collect the kernel.
Step 3. Collecting words
We will collect the semantic core using an example - "car rental in Samara". To begin with, let's think about what requests customers can search for us:
- car rental,
- car rental,
- Rent a Car,
- car rental,
- car rental Samara.
If you can come up with more queries, great. For example, you can specify the brands of cars that you own:
- bmw rental,
- bmw rental.
It is important to choose phrases that characterize your business. If you bring pizza to your home, your list will look like this:
- Pizza delivery,
- order pizza,
- pizza Samara,
- pizza to order.
With the theory sorted out - let's move on to practice.
Create a new project.

Click "New Project" and specify in which folder to save the file
First, specify the region in which you work. Click on the button at the bottom of the window.

We set the region for the service "Yandex.Wordstat"
Find your region in the list, mark it with a tick and click "Save Changes".

Do the same for the rest of the services.

Select your region in the rest of the services that Key Collector uses
Now choose your words. We will use the Yandex.Wordstat service. Open the Batch Collect From Left Column tool.

This is where you add all the queries you come up with. Each request starts on a new line. Click Start Collection to start your search.

The more phrases you enter, the more time it will take to collect. In our case, it took about 3 minutes. Here's what happened:


The column "Date added" is not needed - it only takes up space on the screen. Hide it to make it easier to work. Right-click on it and click "Hide Column".
Key Collector has many tools for collecting phrases, but one Wordstat is enough. You will try the rest when you understand the program. Continue working with the kernel.
Step 4. Removing duplicates
You have collected all the queries that can go into the semantic core. But among them there are many "trash", superfluous. They should be removed.
Let's start with implicit takes. Implicit duplicates are queries that are slightly different from each other, but search engines consider them to be the same. You don't need to have multiple identical queries in the kernel, so find and remove them.
Click the Data tab and select the Implicit Duplicate Analysis tool.

The program will scan your list for duplicates. If it does not find anything, it will offer another selection method - without taking into account word forms. You can enable this mode and manually check the box next to the "Do not take into account word forms when searching" option.
Do not forget to click on the "Repeat duplicate search" button.

Key Collector found two duplicates: "car rental for hours" and "car rental for an hour". One of them needs to be highlighted. You can do it manually. But if there are many duplicates, it takes a long time to select them manually. Better use the Smart Mark tool - it will automatically highlight one phrase in each group of takes.

Close the window, the phrases will remain checked. You can simply delete them. But usually SEOs don't do that. The program has a special folder "Trash", where unnecessary phrases are put. You never know what, suddenly they will come in handy later.
To transfer the marked phrases, return to the "Data collection" section and click "Transfer phrases to another group".

Select the group to which you want to transfer phrases. In our case, this is the "Basket".

Check the boxes next to "Transfer" and "Checked out". Click "Ok".
Done, take in the basket. We pass on to the next point of cleaning the kernel from garbage.
Step 5. Removing stop words
Most likely, most of the queries on the list are not suitable for you. They are for another city or you do not provide such services. Therefore, all unnecessary phrases must be removed.
We will remove unnecessary phrases using a stop word list. If you add a word to this list, the program will check the semantic core and select all phrases in which it occurs. Then they can be deleted or transferred to the trash.
Let's think about which words can be excluded for any type of business:
- Photo, photo, photography, picture, illustration, video- sometimes people need a picture of what you are doing to send it to friends or add to a presentation. These are definitely not your customers - we can safely filter them out.
- Competitor brands- if someone is looking for your competitor, they are unlikely to visit your site. We remove.
- Cheap, inexpensive- can be left if low prices are your real advantage. If not, we remove it.
- Free, download, torrent, torrent- as in the case of pictures, these are not our clients at all.
- Abstract, wikipedia, wiki, wiki- similarly, delete.
In our case, we add to the list the brands of cars that we do not have, and the word "buy" - we are not selling anything. Let's put all this in the Key Collector.
Click on the "Stop Words" button.

Click the Add as List icon.

Click on the green plus sign
Write your stop word list. The stop word is not necessarily a single word. You can specify whole phrases that you do not need.
If you indicate brands, write the names in both Russian and English. It is better to write words without endings - the stop word “moskv” will remove phrases from “Moscow”, “in Moscow”, “for Moscow”.


Checking all phrases that contain stop words
Close the stop words window, the phrases will remain selected. Transfer them to the trash can immediately.
Now begins the most difficult and longest part of compiling the semantic core. You need to look through all the collected phrases and select the "junk" ones. At the same time, it is necessary to supplement the list of stop words to facilitate the process of expanding the kernel in the future.
Review the list. When you find an unnecessary phrase, select it and click on the "Send phrase to stop words window" icon.

Select which words from the phrase you want to add to the list and click Add to Stop Words.

Go through the kernel to the very end, complete the list of stop words, and send extra phrases to the trash can.
There is one more tool that will make your task a little easier. Go to the Data tab and open Group Analysis.

In this window, phrases are grouped according to the specified criteria. You can select several phrases at once with one click. The default is grouping by individual words. All phrases with the same words fall into one group - this is what we need.
Go through this list and mark unnecessary words. This will select all the phrases in which they occur. Don't forget to add them to your stop word list.

A black square means that in this group some phrases are highlighted, and some are not.
This will leave only the necessary phrases in the semantic core and create a complete list of stop words. Let's move on to the next point.
Step 6. Determine the exact frequency
When collecting phrases using Wordstat, you get baseline frequency. This is an inaccurate indicator, you should not be guided by it. Let's find the exact frequency for our semantic core.
To do this, we will use the Yandex.Direct Statistics Collection tool.

Indicate that you want to fill in the columns of the "word" type (in quotes). The quotation marks give us the exact frequency. We launch.

As you can see, the exact frequency is very different from the base one. You will use it to determine the popularity of requests.

Our semantic core is ready.
Step 7. Export
Export the core from Key Collector. Click "File" → "Export" and specify the folder where you want to save the table with phrases. The format (CSV or XLSX) can be set in the settings.

Let's repeat again
So, we have put together a semantic core for a car rental company in Samara. Let's list the sequence of actions:
- 1. Create a separate Yandex account and connect it to Key Collector.
- 2. Come up with a list of phrases that characterize your business.
- 3. Collect phrases from Yandex.Wordstat.
- 4. Remove implicit duplicates.
- 5. Create a list of stop words, remove "junk phrases".
- 6. Download the exact frequency from Yandex.Direct.
- 7. Export a ready-made semantic core and a list of stop words.
Now you know how to work with Key Collector and will be able to compose the semantic core for your site without the help of a SEO.
Hello everyone!
Once you have created an account, you can proceed to the instructions below:

Fine! The Key Collector has been successfully configured, which means you can proceed directly to compiling the semantic core.
Compilation of the semantic core in Key Collector
Before you start collecting key phrases for Yandex.Direct, I recommend reading, in it you will find a lot of useful information about key phrases (only for beginners). Have you read it? Look at another example of collecting a semantic core for the repair of household appliances:
Then it will not be difficult for you to collect masks of key phrases, which are very necessary for parsing through the Key Collector.
- Be sure to specify the region where keywords are collected:
- Click on the button “Batch collection of words from the left column of Yandex.Wordstat”:

- Enter the masks of key phrases and arrange them into groups:
 This is the result. Click “Start Collection”:
This is the result. Click “Start Collection”:  This is done for the convenience of processing key phrases. This way, requests will not be mixed in one group and it will be much easier for you to process them;
This is done for the convenience of processing key phrases. This way, requests will not be mixed in one group and it will be much easier for you to process them; - Wait for the end of the collection of key phrases. Once the process is complete, you can collect the exact frequency of requests, as well as find out the approximate cost per click on the ad, the approximate number of ad impressions, the estimated budget and the number of competitors for a specific request. All this can be found with the help of a single button “Collect Yandex.Direct statistics” (we added it to the quick access panel):
 Check all the boxes in accordance with the screenshot above and click “Get data”;
Check all the boxes in accordance with the screenshot above and click “Get data”; - Wait until the end of the process and view the results. In order to make it convenient to do this, click on the column auto-tuning button, which leaves visible only those columns in which data is present:
 We need the statistical data that we have now collected in order to analyze the competitive situation for each key phrase and estimate the approximate advertising costs for them;
We need the statistical data that we have now collected in order to analyze the competitive situation for each key phrase and estimate the approximate advertising costs for them; - Next, we will use such the coolest and most convenient Key Collector tool, "Group Analysis". We added it to the Quick Access Toolbar, so just navigate to it from there:
 Key Collector will group all key phrases by words and it will be convenient for us to process each group of requests. Your task: go through the entire list of groups; find query groups that contain non-target words, that is, negative keywords, and add them to the corresponding list; mark these request groups in order to delete them later. You can add a word to the list by clicking on the little blue button:
Key Collector will group all key phrases by words and it will be convenient for us to process each group of requests. Your task: go through the entire list of groups; find query groups that contain non-target words, that is, negative keywords, and add them to the corresponding list; mark these request groups in order to delete them later. You can add a word to the list by clicking on the little blue button:  Then a small window will appear where you need to select a list of negative keywords (list 1 (-)) and click on the "Add to stop words" button:
Then a small window will appear where you need to select a list of negative keywords (list 1 (-)) and click on the "Add to stop words" button:  Thus, you work through the entire list. Remember to tag groups with inappropriate words. Key phrases are automatically marked in the table of search queries;
Thus, you work through the entire list. Remember to tag groups with inappropriate words. Key phrases are automatically marked in the table of search queries; - Then you need to remove the marked non-target phrases in the search query table. This is done by clicking the "Delete phrases" button:

- We continue to process the phrases. As you remember, Yandex Direct at the beginning of 2017 had the status “Few impressions” (we dealt with it), and in order to avoid this status, it is necessary to separate requests with a low frequency (LF requests) into a separate group. First, apply a filter to the Base Frequency column:
 Filter parameters: Base frequency, less than or equal to 10. These filter parameters I set based on the region of impressions - Izhevsk:
Filter parameters: Base frequency, less than or equal to 10. These filter parameters I set based on the region of impressions - Izhevsk:  Then we mark all filtered phrases:
Then we mark all filtered phrases: 
- Create a subgroup in the group where the work is currently taking place with a simple keyboard shortcut CTRL + Shift + T:
 Then we transfer the filtered phrases from the “Buy iphone 6” group to the “Few impressions” group. We do this by transferring phrases to another group:
Then we transfer the filtered phrases from the “Buy iphone 6” group to the “Few impressions” group. We do this by transferring phrases to another group:  Then we specify the transfer parameters as in the screenshot below (Run-transfer-checked):
Then we specify the transfer parameters as in the screenshot below (Run-transfer-checked):  Remove the filter from the “Base Frequency” column:
Remove the filter from the “Base Frequency” column: 
Exactly in this way you process the rest of the groups. The method, of course, may seem dreary at first glance, but with a certain skill, you can quickly and quickly compose a semantic core for Yandex Direct and already create campaigns in Excel, and then fill them in. It takes me about 2 hours to process the semantic core in this way, but it depends solely on the amount of work.
Here's another video for you, but already an example of collecting negative keywords:
Export key phrases to Excel
It remains for us to export the key phrases to a file for working with Excel. Key Collector offers two export file formats: csv and xlsx. The second option is much more preferable, since working in it is much more convenient and more familiar to me personally. You can specify the file format in the same program settings, in the “Export” tab: 
You can export key phrases by clicking on the green icon in the quick access bar: 
Each group is exported separately, that is, a separate group is a separate xlsx file. You can, of course, shove all groups of requests into one file using the “Multi-Groups” tool, but then it will be extremely inconvenient to work with these files, especially if there are many groups.
Next, you need to export negative keywords. To do this, you need to go to “Stop Words” and copy negative keywords to the clipboard in order to paste them into Excel later: 
This is how I work with Key Collector, which I taught you too. I sincerely wish that this lesson will help you in mastering this wonderful tool and that your semantic core will bring exclusively targeted traffic and many, many sales.
See you soon, friends!
If you do not know where to start the process of setting up the program, then we advise you to pay attention to this section. Here we will look at the general principles of settings and show how to correctly apply them in certain situations.
The first thing to start with configuring the program is to look at the tab "Settings - Parsing - General"... Here you will see the settings related to downloading data from the collected systems, setting the data collection mode and filtering specials. characters and some others. By default, the options are set to universal values, and they can, in principle, not be changed, only if you do not have any unusual preferences or tasks. If there is, then now you know where you can turn off the automatic deletion of the specials you need. characters or where to increase the timeout (time) of waiting for a response from the service, if you often get the error "The operation has timed out" or "The operation has timed out" in the event log.
- Delays between requests from ... to ... ms
- Number of threads
- Use Primary IP Address
- In case of errors in receiving a response from the service (response timeout, etc.), exclude the proxy server
- Block "Streams deactivation settings"
Almost all systems that you will remove are interested in that you do not create too much load on them with your actions. They can use captcha or temporary blocking of an IP address or account as a protective mechanism. To prevent this from happening, you need to try not to exceed the "trust limit" conditionally issued to you. Unfortunately, this limit is issued for everyone individually, so you cannot give 100% safe settings that will suit everyone, but following a few simple recommendations will still help you reduce the likelihood of receiving sanctions from the systems.
Do not set too unnaturally small delays between requests for those systems that monitor the load level very carefully: Yandex.Wordstat, Yandex, Google, Mail search results, Google search suggestions, Yandex.Direct and Rambler.Adstat. If you plan to execute a large number of requests, then make the delays natural. For example, for Yandex.Wordstat it is from 20 to 25 seconds, for Yandex.Direct - from 5 to 10 seconds, for search results - from 8 to 10 seconds, etc.
Do not run more streams than you use IP addresses (your IP address + proxy servers, if any), because using more threads will result in less exposed latency between requests. Let us draw your attention to the fact that within the framework of the exclusion, the flows for the removal of KEI components are set to "Settings - KEI", not in.
Use the option wisely. If you work without using proxy servers, then you can't get away without it, but if you work with proxy servers, then you should think about whether you want to risk the main IP address for a slight increase in the speed of reading statistics (if there are at least several proxies) ...
Perhaps the only case when this option should be enabled when working through a proxy is when you use a very small (up to 10) number of good stable proxy servers. In this case, sparing delays and other settings are usually set, so the probability of blocking is quite small, and the speed increase can be up to 10%.
When you work through proxy servers, the quality of which is obviously not the best, i.e. when you admit that some of them may become unavailable at any time, you can significantly reduce the time for collecting statistics if you delete their queues for use within the framework of the running collection process. This can be done by the option "In case of errors in receiving a response from the service (response timeout, etc.), exclude the proxy server"... The proxy server excluded after the start of the statistics collection process will no longer take your time for repeated attempts to use it.
If you do not want to give such unreliable proxy servers a second chance, then enable this option. In this case, you can also enable the option "Disable proxy servers discarded during parsing in the settings" v "Settings - Network", which will also allow turning off such proxy servers globally at the settings level.
In the event that you work through proxy servers or through accounts (Yandex.Wordstat and Yandex.Direct), it is important to keep the same load level on each of them from the beginning of the statistics collection process to its end. For these purposes, the "Streams deactivation settings" block is used.
For example, if you work with expensive high-quality proxy servers, and one of them for one reason or another becomes blocked or excluded due to a large number of errors, then you should not share its burden with other proxy servers, because this can make them more vulnerable to blocking. In this case, it is recommended to select either the mode "Reduce the number of threads by 1 until 0 each time the proxy server is excluded", or the mode "Decrease the number of threads by 1 when excluding the proxy server only when the number of remaining proxy servers is less than the number of threads set at the start."
If you work with a large number of low quality public proxies that do not last long, then you might consider using the mode "Do not reduce the number of threads when excluding proxy servers" since dozens or even hundreds of people work through such proxies at the same time. And here we are already talking about which of the users will be able to derive the most benefit from them.
The next point to consider is the use of proxies in general. In general, they are specified in "Settings - Network"... Proxies can be good (stable and fast) and bad (dead, slow, or blocked).
For reasons of high demand for good proxy servers, they always come with password protection or client IP address protection. There are no good public proxies! Such proxy servers can be either fully dedicated (provided only to you and no one else), or cooperative (access is shared between a group of users). For some tasks, proxy servers with cooperative access may be fine, and you can save on this.
Unfortunately, people often buy bad public free proxies. Those. they pay some service money to provide them with a list of addresses of public free proxy servers found by this service (i.e., theoretically, you could find these proxies yourself and completely free of charge). Due to their publicity, almost all of these proxy servers are either overloaded and work very slowly, or are blocked and sealed due to the large number of requests passing through them, or are no longer available at all, because the list that you downloaded has already lost its relevance (outdated). There is nothing surprising when out of 1000 such proxy servers only 3-4 pass the check, and even those die after 5 minutes.
We recommend, if possible, not to use such large collections of proxy servers, at least without access protection. Unfortunately, we cannot recommend a 100% good service where you can get good proxy servers, because such a universal option, which we will offer to users, will soon be blocked (following the example of previously recommended servers). You can find proxies through a search engine or forum based on fresh feedback from real users. It will be more reliable than any options we would recommend to all of our users.
Note that it is not at all necessary to always use proxy servers. Sometimes, on the contrary, it is easier and faster to take statistics without them. This often happens in situations where parsing volumes are small, or when the statistics being taken are returned quickly and without harsh sanctions. For example, these are statistics from Google.Adwords, Yandex.Direct (including the frequency of Yandex.Wordstat via Yandex.Direct), etc. You can also try to bypass blocking and captcha by changing the IP address, if the provider dynamically issues it to you.
Now let's move on to the issue of captcha recognition. You can do it manually or use automatic recognition services, which usually charge a very small fee (about $ 1-3 per 1000 captchas). You can set up work through one of these services in "Settings - AntiCaptcha".
Finally, let's clarify small details regarding the performance of the program. You can significantly increase the speed of the program if you enable the option in.
As for all other settings, they are more individual. All of them in the program interface are provided with tips with descriptions. If you have any questions, you can ask them to the technical support of the program. We also recommend that you familiarize yourself with the recommendations for setting up the process of collecting statistics in the manual in the sections describing various statistics systems.
Yandex.Wordstat
The program supports collection of statistics from the Yandex.Wordstat system.
Using Key Collector, you can collect words for a given query or a group of queries with their base frequencies, find out the base, " " and "!" frequency for available key phrases, and remove seasonality data.
If you do not know what settings are better for collecting Yandex.Wordstat statistics, then you can use the general advice from this section.
Since the end of 2013, the Yandex.Wordstat service has ceased to provide statistics to unauthorized users (those who have not logged into any Yandex account). For this reason, in order for Key Collector to receive statistics from Yandex.Wordstat, you need to set data about Yandex accounts in the settings.
When working with Yandex.Wordstat, the program uses the
Login: Password
OtherLogin: Password
Next, let's return to setting up collection from Yandex.Wordstat itself by going to the tab "Settings - Parsing - Yandex.Wordstat"... Here you can tweak many parameters as you like, but the parsing depth. All options on this tab are provided with tips that you can explore yourself if you have any questions.
To reduce the likelihood of receiving a captcha and a ban (blocking an IP address), we recommend that you do not set more than 1 stream per 1 IP address, but set the delays between requests in the range from 20,000 to 25,000 ms.
Attention: do not enable the "Get statistics via Yandex.Direct" mode unless it is clearly necessary. Be sure to read the description of this function before using!
If you want to work through proxy servers, you should know about the peculiarities of working with them when working with Yandex.Wordstat.
"Settings - Parsing - Yandex.Direct"
# at the beginning of each line. When using this method when working with Yandex.Wordstat and Yandex.Direct, regardless of whether the use of proxy servers is enabled in "Settings - Network" "Settings - Parsing - Yandex.Direct"
Set proxy servers in "Settings - Network"... This means that if in "Settings - Network"
An important feature of this method of setting a proxy is the ability to rotate (switch) proxy servers when working with Yandex.Wordstat or Yandex.Direct. It also becomes possible to deactivate "bad" proxies, which, for example, have stopped responding. The option is responsible for this. "Proxy use mode".
"Use Primary IP Address" c when working directly with Yandex.Wordstat and and "Use Primary IP Address" v "Settings - Parsing - Yandex.Direct" when working with Yandex.Direct.
"Settings - Network" "Settings - Parsing - Yandex.Direct".
"Settings - Parsing - Yandex.Wordstat" for Yandex.Wordstat and in "Settings - Parsing - Yandex.Direct" for Yandex.Direct options and select different from
We also recommend increasing the parameter "Number of retries" in up to 30-90. Besides, "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
Region setting
In order to more accurately assess key phrases, it is necessary to establish the region of interest to you. This can be done using the button in the status bar.

Attention: the regionality settings are common for all user tabs and are saved in the project file, so be careful with setting the region before you start taking statistics.
Setting stop words
You can reduce unwanted parsing times by enabling the option.
Attention: when using the option "Apply when composing a request" you cannot use too many stop words, because Yandex.Wordstat has a limit on the length of the request. If you need to work with a large number of stop words, then do not use this option, but use the button "Mark in the table" in the stop words window after the parsing is completed, having previously selected the required type of match search.
Collecting key phrases
The program allows you to collect key phrases and their corresponding base frequencies from the left and right columns of the Yandex.Wordstat service.

To retrieve data from the left column, use the button with the service logo in the group of buttons.

Another way to collect information from the left column is the quick query string, which is disabled by default, but you can enable it in "Settings - Interface - Other" using the option "Include a quick request field for Yandex.Wordstat".

Note: By default, when using a quick query string, the data table is cleared. To disable this feature, you need to use the option "Do not remove phrases from the table when using a quick query string" v "Settings - Parsing - Yandex.Wordstat".
To collect data from the right column, use the button with the Yandex.Wordstat service icon painted in blue, located in the group of buttons "Collecting keywords and statistics".

You can collect only the right column or both columns at once. You can select the appropriate mode in the drop-down menu of the button by checking or unchecking the checkbox. "Collect data from the left column".

Collecting data from the right column is available for both the specified list of words and words already added to the currently viewed table.
There are 2 modes for collecting phrases from the left and right columns of Yandex.Wordsat: classic (1st mode) and alternative (2nd mode). Learn more about these modes. Do not use alternate mode unnecessarily.
Collecting frequencies
The program allows you to collect base frequencies, as well as frequencies like "" and "!" for key phrases in the table from the Yandex.Wordstat service.
To select frequencies, use the drop-down button with the magnifying glass icon in the group of buttons "Collecting keywords and statistics".

Frequencies of the form "" are formed according to the principle: my request -> "my request".
Frequencies of the form "!" are formed according to the principle: my request -> "! my! request".
You can customize how the button works "Collect all kinds of frequencies" v "Settings - Parsing - Yandex.Wordstat".
Attention: at the moment, retrieving frequencies directly from Yandex.Wordstat is unsafe, because can get IP blocking quickly. Today it is recommended to use for picking up frequencies. The data will completely coincide with the Yandex.Wordstat data, but the retrieval process is ten times faster and safer.
Harvesting seasonality
The program allows you to collect information about the popularity of a request for the past period, build a graph based on this data and make an assumption about the seasonality of a given request based on the data received.
To retrieve information about the seasonality of the request, click the button with the chart icon in the group of buttons "Collecting keywords and statistics".

When retrieving information about the seasonality of the request, the values of the arithmetic mean frequency and its median are also calculated. You can change the period during which statistics are reviewed for calculating these values in the Yandex.Wordstat collection settings.
If necessary, you can get statistics grouped by week, not by month. In this case, the launch should be performed through the appropriate item in the drop-down menu of the Yandex.Wordstat seasonality data collection button.

You can view extended information about seasonality by clicking on the cell corresponding to this phrase. If necessary, you can export extended frequency data for all phrases to a CSV file. To do this, you need to use the appropriate button in the drop-down menu of the button for starting the collection of seasonality.
Rambler.Adstat
The program supports collection of statistics from the Rambler.Adstat system.
Using Key Collector, you can collect words for a given query or a group of queries with their frequencies, as well as find out the frequencies for existing key phrases.
In order for the program to be able to receive data from this service, you must enter the authorization data in the Rambler.Adstat collection settings in "Settings - Parsing - Rambler.Adstat".
Selecting a month for the report
Before starting to collect information, you can select a specific month for which you would like to receive statistics.
To do this, open the menu of drop-down buttons for collecting Rambler.Adstat statistics and select the required item.

Note that this procedure is optional: if the user does not select a month, the program will take statistics with a default value, i.e. for the last available period.
Collecting key phrases
The program allows you to collect key phrases and their corresponding frequencies from the Rambler.Adstat service.

To retrieve data, use the button with the icon in the form of the letter R on a white background in the group of buttons "Collecting keywords and statistics".

In the window that opens for batch input of words, you can enter manually or load the words of interest from a file. In this case, you can choose where you want to place the parsing results for each of the input phrases: on the current tab or spread over several tabs. After pressing the button to start the process, the program will start collecting data for the specified key phrases.
If you work with huge projects (tens or hundreds of thousands of phrases) and collect phrases in batch mode, then you may find the option useful "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
Collecting frequencies
The program allows you to collect frequencies for key phrases available in the table from the Rambler.Adstat service.

To remove frequencies, use the drop-down button with an icon in the form of a letter R on a black background in a group of buttons "Collecting keywords and statistics".
LiveInternet
The program supports the collection of statistics from the counters of the LiveInternet statistics system. Using Key Collector, you can collect words and traffic from a specified counter.
Collecting statistics from the counter

To call the statistics collection window "Collecting keywords and statistics".

The program supports both collecting statistics from one site and batch processing of several counters. In this case, in batch mode, you can, at your discretion, select the mode of adding phrases from statistics to one tab or distribute requests to different tabs. In both cases, the site address (counter name) must be specified without http: // and www, i.e. simply site.ru.
The program supports reading statistics from three types of LiveInternet reports: search phrases, positions in Yandex, positions in Google.
In addition, you can choose how to count the number of transitions for a particular phrase: the maximum value for the specified period, the sum of the transition values for the specified period, or the first encountered value of the transitions for the period. In all modes except the last one, the value of transitions is calculated by the program when the statistics collection process is complete, so if you interrupt it earlier, then only phrases (without information about transitions) will be written to the table. Let's look at an example.
Let, in the report, the phrase "kefir" in March had 35 transitions, and in February - 40 transitions. If you have selected the mode of collecting the maximum number of transitions, the program will write down the value of 40 transitions in front of the phrase "kefir" (since 40> 35). If the mode of collecting the sum of transition values was selected, the program will write 75 (35 + 40 = 75). Finally, if the mode of collecting the first encountered value was selected, then 35 transitions will be recorded in response, since the program scans the report from the latest date of the period to the earliest (in the past).
Before you start collecting statistics, you also need to set the collection period for which the program will try to get statistics. In this case, you can also select the type of statistics grouping: by months or by days.
If you want to get only phrases containing or not containing any word, then you can use the function of filtering report results at the LiveInternet level.
Option
Option
Option
"Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
If you work using a proxy of not very good quality, then the option can also help you "In case of errors in receiving a response from the service, exclude the proxy server" v "Settings - Parsing - LiveInternet".
Yandex.Metrika
The program supports the collection of statistics from the counters of the Yandex.Metrika statistics system. Using Key Collector, you can collect words and traffic from a specified counter.
Collecting statistics from the counter

Press the button with the service logo in the group of buttons "Collecting keywords and statistics" and enter your authorization data in the statistics system.

To collect Yandex.Metrika statistics, you need to log in to an account that has access to the counters from which you would like to collect statistics.
The program supports both regular and batch collection of Yandex.Metrika statistics. When using regular collection, you can either select the desired site from the drop-down list, or enter its ID manually.
The next step is to select the period for which you want to get statistics. You can enter the period yourself or use a template (quarter, year, etc.).
Option "Update statistics for phrases existing in the table" allows you to update conversion statistics for phrases that exist previously in the table. For example, the phrase "kefir" was added to the table earlier. If the option is disabled, and although this phrase is found in the report, the program will not write the transition value for it. If the option was enabled, the program will update this value.
Option "Do not add new phrases to the table" is in addition to the previous option. By enabling it, you will prevent the program from adding phrases to the table that were not there before. This can be useful if you just want to update or collect data on transitions to previously collected statistics, without diluting the list of phrases in the table with new phrases, which may require additional processing later.
In the first case, the program simply generates a request to the Yandex.Metrika API, passing the collection period boundaries in the parameters. In response, she receives a list of phrases immediately with statistics about transitions, which can be immediately written into the data table. This mode is faster, but as a result, some low-frequency phrases may not be received due to the peculiarities of the API itself.
In the second case, the program looks through the statistics for the specified period manually on a daily basis, and then, when the collection is complete, calculates the transition values. Daily viewing in parts sometimes allows you to get more phrases that the API does not normally produce (low-frequency phrases), but this takes significantly more time. It should also be borne in mind that if the collection process was interrupted, then the statistics of transitions and refusals will not be calculated. Therefore, when working with this mode, you should wait until the collection process is complete.
Option "Do not add a phrase if it already exists on any other tabs" may come in handy if you do not want the table not to receive phrases that you have already processed on other tabs.
Because collection of statistics is associated with the alternate viewing of statistics for a specified period, then if you work with huge projects (tens or hundreds of thousands of phrases) or remove statistics from "large" counters, then you may find the option useful "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
Google.Analytics
The program supports the collection of statistics from the counters of the Google.Analytics statistics system. With Key Collector, you can collect words, visit count, bounce rate, and landing pages from a specified counter.
Collecting statistics from the counter

Press the button with the service logo in the group of buttons "Collecting keywords and statistics" and the window for collecting Google Analytics statistics will open in front of you.

To collect Google Analytics statistics, you must provide a username and password for an account that has access to the counters from which you would like to collect statistics. Optionally, you can enable the option "Save authorization data in the program settings"... If you use this option, because program settings are stored on your PC in an open (unencrypted) form, it is recommended not to enter data from a real Google account, but to use a specially created clean account for these purposes, which is entrusted with viewing the counters you need (guest access is provided).
After entering your username and password, click on the drop-down list with sites and select the counter from which you are interested in statistics. Then select the period for which you want to get statistics. You can enter the period yourself or use a template (quarter, year, etc.).
Option "Update statistics for phrases existing in the table" allows you to update conversion statistics for phrases that exist previously in the table. For example, the phrase "kefir" was added to the table earlier. If the option is disabled, and although this phrase is found in the report, the program will not write the transition value for it. If the option was enabled, the program will update this value.
Option "Do not add new phrases to the table" is in addition to the previous option. By enabling it, you will prevent the program from adding phrases to the table that were not there before. This can be useful if you just want to update or collect data on transitions to previously collected statistics, without diluting the list of phrases in the table with new phrases, which may require additional processing later.
In the first case, the program simply forms a request to the Google.Analytics API, passing the collection period boundaries in the parameters. In response, she receives a list of phrases right away with statistics on conversions, bounce rates and landing pages, which can be immediately written into the data table. This mode is faster, but as a result, some low-frequency phrases may not be received due to the peculiarities of the API itself.
In the second case, the program looks at the statistics for the specified period manually on a daily basis, and then, when the collection is complete, calculates the transition values and% of failures. Daily viewing in parts sometimes allows you to get more phrases that the API does not normally produce (low-frequency phrases), but this takes significantly more time. It should also be borne in mind that if the collection process was interrupted, then the statistics of transitions and refusals will not be calculated. Therefore, when working with this mode, you should wait until the collection process is complete.
Option "Do not add a phrase if it already exists on any other tabs" may come in handy if you do not want the table not to receive phrases that you have already processed on other tabs.
Because collection of statistics is associated with the alternate viewing of statistics for a specified period, then if you work with huge projects (tens or hundreds of thousands of phrases) or remove statistics from "large" counters, then you may find the option useful "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
Search hints
The program supports collection of search suggestions from six popular search engines: Yandex, Google, Mail, Rambler, Nigma, Yahoo, Yandex.Direct.
Collecting search suggestions
In order to collect search tips from the search engines you are interested in, click the button with the icon of three multi-colored honeycombs in the group of buttons "Collecting keywords and statistics".

In the window that opens for batch input of words, you can enter manually or load the phrases you are interested in from a file. In this case, you can choose where you want to place the parsing results for each of the input phrases: on the current tab or spread over several tabs. After that, you must mark the checkboxes of the search engine in which the search should be performed, and click on the button to start collecting information (in order for the checkbox "Yandex.Direct" became available, you must first register one or more accounts in "Settings - Parsing - Yandex.Direct").
Attention: collection of hints from Yandex.Direct has a very small limit on the number of requests. It is recommended to use collection of search suggestions from Yandex.Direct only for a limited number of phrases, if necessary. Also, if you work with enumeration, it is recommended to disable enumeration whenever possible and collect Yandex.Direct hints separately without them (or with them, but with large delays between requests).

Option " With selection of endings"allows you to collect even more hints due to the fact that the program will select the endings of words automatically. For example, by entering the word" sausage "and checking the Cyrillic alphabet for endings in the settings, you instruct the program to examine the words:" sausage "," sausages "," sausage ", etc. (the last letter is searched without space substitution). The search for endings is useless if full words are specified as the source words. For example, if you specify" sausage "and enable the search for endings, the program will make queries for" sausage "," kobasau ", which will not bring results.
Attention: do not enable the option of matching endings unless it is clearly necessary, because its use greatly affects the number of requests made and the total time it takes to complete the task.

If you want to quickly collect only the TOP search suggestions, use the " Collect only TOP prompts without brute force and space after the phrase"in the settings: this function hides or deactivates unnecessary settings (the option for selecting endings and brute-force settings), simplifying the collection process.
The program supports the collection of similar search queries from the search results of the PS Yandex, Google, Mail.
In order to collect search tips from the search engines you are interested in, click the button in the group of buttons "Collecting keywords and statistics".

In the window that opens for batch input of words, you can enter manually or load the phrases you are interested in from a file. In this case, you can choose where you want to place the parsing results for each of the input phrases: on the current tab or spread over several tabs. After that, it is necessary to mark the checkboxes of the search engine in which the search should be performed, and click on the button to start collecting information.

WebEffector
The program supports the collection of statistics from the WebEffector service: the promotion budget (the number of clicks and cost per click - CPC (Cost Per Click) are temporarily not charged).
"Collecting keywords and statistics".


SeoPult
The program supports collecting statistics from the SeoPult service: promotion budget, number of clicks, cost per click - CPC (Cost Per Click), geo-dependence and the number of anchors from competitors.
In order to collect statistics for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".


If you check the box "Receive the number of anchors", then the program will also receive the number of anchors from competitors in the specified visibility zone (the parameter is responsible for this "Read result for ...").
Attention: counting the number of anchors significantly increases the task execution time. Do not enable this option unless explicitly required.
Rookee
The program supports the collection of several types of statistics from the Rookee service (RooStat):
- collecting statistics (promotion budget, number of clicks, cost per click - CPC (Cost Per Click), geo-dependence and belonging of a query to commercial topics) for phrases in the table;
- calculating the best word form for phrases available in the table;
- batch collection of extensions for specified key phrases (collection of new phrases);
- automatic compilation of the semantic core for the site URL (collection of new phrases).
Collecting statistics
In order to collect statistics for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

In the window that opens, select the region, scope and preferred search engine.

Calculating the best word form
In order to collect the best word forms for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics"

Collecting extensions for key phrases

In order to start collecting extensions (new key phrases) for the existing list of phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics" and select the appropriate item from the button's drop-down menu.

In the window that opens for batch input of words, you can enter manually or load the words of interest from a file. In this case, you can choose where you want to place the parsing results for each of the input phrases: on the current tab or spread over several tabs. After pressing the button to start the process, the program will start collecting data for the specified key phrases.
If you work with huge projects (tens or hundreds of thousands of phrases) and collect phrases in batch mode, then you may find the option useful "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
Automatic compilation of the semantic core by URL

In order to start the automatic collection of the semantic core (new key phrases) from the site URL, click on the button with the service logo in the group of buttons "Collecting keywords and statistics" and select the appropriate item from the button's drop-down menu.

In the window that opens, select the desired region, scope, target search engine and enter the site URL. If necessary, you can specify several addresses at once (each on a new line).
If you work with huge projects (tens or hundreds of thousands of phrases) and collect phrases in batch mode, then you may find the option useful "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
MegaIndex
The program supports the following types of statistics collection from the MegaIndex service:
- collection of statistics (promotion budget, number of clicks according to LiveInternet data, number of requests per month, cost) for phrases in the table;
- batch analysis of site visibility (collection of new phrases and positions that these sites occupy).
Collecting statistics

In order to start collecting statistics for existing key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

Website visibility analysis

In order to start an analysis of the visibility of sites in search engines (to get phrases for which these sites are in the TOP of the search results), click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

In the window that opens, enter your authorization data and select a search region from the drop-down list. Further, if you want to remove only the phrases for which the indicated sites were in the TOP of the search results, only for a certain period, then enable the option "Shoot a specific period" and select it from the dropdown list. If the option is disabled, the program will sequentially scan all available periods (you can get significantly more phrases, but this will take more time).
If you enable the option "Record positions in Yandex, Google PS according to MegaIndex data", then the program will update these values in the table for phrases where before that positions were not removed at all or there was a "No data" value (phrases for which positive positions were previously removed will not be updated in these columns).
Option "Update statistics for phrases existing in the table" allows you to update statistics for phrases previously existing in the table. For example, the phrase "kefir" was added to the table earlier. If the option is disabled, and although this phrase is found in the report, the program will not record statistics for it (budget, positions, etc.). If the option was enabled, the program will update these values.
Option "Do not add new phrases to the table" is in addition to the previous option. By enabling it, you will prevent the program from adding phrases to the table that were not there before. This can be useful if you just want to update or collect statistics for previously collected phrases, without diluting the list of phrases in the table with new phrases, which may require additional processing later.
Next, you should enter manually or download from a file the site addresses you are interested in (in the format without http: // and www, i.e. simply site.ru). At the same time, you can choose where you want to place the parsing results for each of the input sites: on the current tab or spread over several tabs. After pressing the button to start the process, the program will start collecting data for the specified site addresses.
If you work with huge projects (tens or hundreds of thousands of phrases) and collect phrases in batch mode, then you may find the option useful "Do not update the contents of the table after bulk insert and update operations when parsing" v "Settings - Interface - Other".
Yandex.Direct
The program supports the collection of statistics from the Yandex.Direct service: budget, number of clicks, number of impressions, cost per click, CTR and competition data - collection of information about placed ads for specified key phrases.
If you do not know what settings are best for collecting Yandex.Direct statistics, then you can use the general advice from this section.
In order for Key Collector to receive statistics from Yandex.Direct, you need to set data about Yandex accounts in the settings.
Attention: do not use real accounts, as they can be banned. Create specially created clean accounts for parsing, which in case of blocking will not be a pity to lose.
When working with Yandex.Direct, the program uses the "Settings - Parsing - Yandex.Direct" accounts. You can specify several pieces at once (each on a new line), however, we would not recommend specifying too many accounts at once (more than 2-3 per stream) without the need to specify. before using them 1 time per session, the program will log in to them, which takes time.
The format for entering accounts is as follows:
Login: Password
OtherLogin: Password
Those. you need to specify the login account and password to it, separated by a colon. As a login, you need to use a short format (without @ yandex.ru).
The main settings concerning this system are located in "Settings - Parsing - Yandex.Direct"... All options on this tab are provided with tips that you can explore yourself if you have any questions.
To reduce the likelihood of receiving a captcha and a ban (blocking an IP address), we recommend that you do not set more than 1 stream per 1 IP address, and set the delay between requests to a value of at least 5000 ms.
If you want to work through proxy servers, you should know about the specifics of working with them when working with Yandex.Direct.
There are 2 ways to set up proxy servers.
Set them together with Yandex.Direct accounts in "Settings - Parsing - Yandex.Direct"... In this case, you need to use the extended input format:
#IPaddressProxy: Port: LoginProxy: PasswordProxy: LoginYandex: PasswordYandex
We draw your attention to the need to use a leading character # at the beginning of each line. When using this method when working with Yandex.Direct and Yandex.Wordstat, regardless of whether the use of proxy servers is enabled in "Settings - Network" or not, as well as regardless of the chosen in "Settings - Parsing - Yandex.Direct" proxy mode, all requests and authorization in accounts will be performed through the proxy servers specified along with the accounts. When using this method, it is important to be sure of the quality of the proxies used, since no rotation (change of proxy) will take place.
If you work with private dedicated good proxy servers, then this method may be useful to you.
Set proxy servers in "Settings - Network"... At the same time, when performing authorization in the specified accounts (1 time per session with the program for each account), one proxy server will be selected from all specified ones, and then it will be associated with this account until the program is completed or before clicking on button "Force clear authorization data"... This means that if in "Settings - Network" If you add 10 proxy servers, and there will be only 2 accounts, then by default only 2 proxy servers will be used.
An important feature of this method of setting a proxy is the ability to rotate (switch) proxy servers when working with Yandex.Direct or Yandex.Wordstat. It also becomes possible to deactivate "bad" proxies, which, for example, have stopped responding. The option is responsible for this. "Proxy use mode".
If you work with not always stable proxies and are not sure of their quality, then you can try to set the rotation mode and enable the option "Do not use a proxy when logging into accounts"... In this case, authorization will go directly without a proxy, and the requests themselves will go through a proxy or directly, depending on whether the options are enabled "Do not use proxy servers when making requests to Yandex.Direct" and "Use Primary IP Address" v "Settings - Parsing - Yandex.Direct" when working with Yandex.Direct and "Use Primary IP Address" v "Settings - Parsing - Yandex.Wordstat" when working directly with Yandex.Wordstat.
Thus, if you plan to use proxy servers, and if they are of low quality, then use the tab "Settings - Network", and also, at your discretion, enable rotation of proxy servers in "Settings - Parsing - Yandex.Direct".
If you have turned on the rotation and assume that the specified proxies will gradually die, then turn on "Settings - Parsing - Yandex.Direct" for Yandex.Direct and in "Settings - Parsing - Yandex.Wordstat" for Yandex.Wordstat options "In case of errors in receiving a response from the service, exclude the proxy server" and choose a different from "Each time reduce the number of threads when excluding proxy servers" mode of working with streams, so that when one of hundreds of bad proxies is excluded, 1 out of just a few running threads does not end.
Region setting
In order to more accurately assess key phrases, it is necessary to establish the region of interest to you. To do this, press the button "Set region" in the window for launching Yandex.Direct statistics collection or on the button in the status bar.
A window for specifying regions will open in front of you:
Attention: the regional settings for Yandex.Direct and Yandex.Wordstat are independent!
Attention: the regionality settings are common for all user tabs from the "Keywords" group and are saved in the project file, therefore, be careful with specifying the region before starting to take statistics.
Collecting statistics

In order to collect statistics for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

In the window that opens, if necessary, set the region (if necessary), select (word, "word" or "! Word") and specify the information collection mode: special. placement, first place or guaranteed impressions. The data is taken from the panel at: https://direct.yandex.ru/registered/main.pl?cmd=ForecastByWords.
Search
The program can send phrases to Yandex.Direct for processing in three different modes:
- word- in this mode, the program sends the phrase "as is" for analysis (similarly base frequency in Yandex.Wordstat);
- "word"- in this mode, the program encloses the phrase in quotation marks (similarly frequency of the form "" in Yandex.Wordstat);
- "!word"- in this mode, the program encloses the phrase in quotes, and also puts a sign in front of each word ! ... Those. from the phrase beautiful boots it will turn out "! beautiful! boots"(similarly frequency of the form "!" in Yandex.Wordstat).
In this case, if you enabled the option, then the column will be filled basic, " " or "!" the frequency of Yandex.Wordstat, depending on the selected collection mode.
Collect information about competitors
The program can scan competitors' ads placed in Yandex.Direct for each of the phrases sent for analysis. This operation significantly increases the time required to complete the task, therefore it is recommended not to enable the option unnecessarily. Scanning is carried out using the service http://direct.yandex.ru/search?text=.
Attention: when collecting information about competitors (ads), the region specified for Yandex search results is taken into account, and not the region specified for collecting Yandex.Direct statistics.

To view the titles, content and links of ads, click on the cell with Yandex.Direct competition data - an additional window will open.
Note: Collecting competition data significantly increases the time it takes to collect information, so do not enable this option unnecessarily.
The purpose of starting statistics collection is to fill in the frequency columns of Yandex.Wordstat
If you enable this option, then the program will determine the list of phrases based on the corresponding columns in Yandex.Wordstat, and not on the columns in Yandex.Direct.
Let's look at an example for clarity. Let the data table contain 150 phrases, and in "Settings - Parsing - General" the collection mode is selected for uncollected (i.e. for those phrases for which statistics are not yet available). Let's assume that Yandex.Direct statistics (budget, cost per click, etc.) have already been collected for some 100 phrases, but the statistics in the Yandex.Wordstat columns are empty.
If this option is disabled, the program will determine the list of phrases that need to be processed by the fullness of the Yandex.Direct budget cell, i.e. the remaining 50 phrases will be processed (150 - 100 = 50).
If this option is enabled, and, say, the search mode is selected "!word", then the program will view and add to the queue for analysis all phrases that do not have statistics in the column frequency "!" by Yandex.Wordstat.
Thus, this option should be enabled if the primary information you are interested in in Yandex.Direct is the number of impressions that you would like to record in the frequency columns of Yandex.Wordstat.
Attention: due to the fact that Yandex.Direct is accepted at the input of a bunch of phrases and, if necessary, "glues" phrases in them, the program may not collect Yandex.Direct statistics for some phrases (accordingly, Yandex.Wordstat statistics will not be collected either). Also Yandex.Direct cannot accept phrases containing specials for processing. symbols, and long phrases of more than 7 words.
Attention: since until the request is sent for processing, the program cannot know which of the phrases Yandex.Direct will "stick together" and which are not, then immediately before the formation of the request, the program erases the statistics data for the phrases that are contained in the current request for processing in order to prevent so that part of the data in the table has fresh actual results, and part - the results from the last retrieval (if, for example, 5 out of 100 sent phrases are "glued", then the program will not be able to find out the statistics for each of the 5 separately).
Record Yandex.Direct statistics for requests of the form
This option has a meaning when you enable the option "The purpose of starting statistics collection is to fill in the frequency columns of Yandex.Wordstat" and select several types of requests at once in the field "Search"... Because In this case, the program alternately receives statistics for the specified types of requests, it becomes unclear for which of the selected types of requests Yandex.Direct statistics data will be recorded (budget, CPC, etc.).
Using this option, you can explicitly specify which query will form the basis for filling in the Yandex.Direct statistics columns.
Google.Adwords
The program supports the collection of statistics from the Google.Adwords service: budget, frequency and competition coefficient.
Preparing an account for use in the program
To collect Google.Adwords statistics, you need to register a separate account. The use of this account is highly discouraged for the reason that the service can block it for a large number of automated requests.
After registering an account, you need to go through a browser to Google.Adwords and log in under the created account. Next, you will be prompted to select the interface language ( be sure to indicate Russian), set the time zone and the desired currency type in which the cost of a click will be displayed.
The prepared account should be registered in "Settings - Parsing - Google.Adwords" in the format YourLogin: Password(login and password separated by a colon).
Attention: do not register more than 1 account without an obvious need (a huge number of requests, in which you have already received a ban once). Using multiple accounts can slow down the program.
Region setting

In the current versions of the program, the choice of the region and language of queries is carried out directly through the window for starting the collection of statistics.
- If you want the program not to change the region or language of requests specified in the account, then enable the option "do not change account settings".
- If you want to change or set a specific region and language, then enter or select the required region or query language from the list. When specifying a region, it is allowed to enter other cities that are not in the list of available options (the official name should be entered without errors).
- If you want to collect statistics without restrictions on the region, then delete the entered region and leave the field blank.
Collecting key phrases

In order to collect similar key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

In the window that opens, if necessary, set the country and language, select the desired type of match, set filters, if required. Also here you need to enter manually or load the phrases you are interested in from a file. In this case, you can choose where you want to place the parsing results for each of the input phrases: on the current tab or spread over several tabs.
If you work with huge projects (tens or hundreds of thousands of phrases) and collect phrases in batch mode, then the option "Do not update table contents after bulk insert and update operations during parsing" in "Settings - Interface - Other" may be useful to you.
Collecting statistics

In order to collect statistics for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

In the window that opens, enter the country if necessary, select the desired type of match.
Attention: the process of collecting information occurs without using the proxy servers specified in the program settings. If you want to receive Google.Adwords statistics through a proxy server, specify it in the Internet Explorer settings.
Begun
The program supports the collection of statistics from the Begun service (average cost per click).
In order to collect statistics for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".


In order to find out the site identifier, you need to manually log in to the system through a browser and create a new text advertising campaign with any one ad inside. Then click on the name of the new site - in the page address bar you will see the identifier:

Attention: make sure that the site, the ID of which you enter, is in an active state. To do this, find a site with a list of campaigns in your account dashboard and click "Activate" if this link is available.
In contact with
The program supports the collection of statistics from the social network VKontakte: the number of search results for people and groups for the specified key phrases.
Before collecting information, you must fill in the authorization data in the program settings.

In order to collect statistics for the available key phrases, click on the drop-down button with the service logo in the group of buttons "Collecting keywords and statistics".
LinkPad (Solomono)
The program supports collecting statistics from the LinkPad (Solomono) system (http://www.linkpad.ru/tools/default.aspx?t=ps&i=): collecting information about the visibility of competitors' sites in the specified scope of search results.
In order to collect statistics for available key phrases, click on the button with the service logo in the group of buttons "Collecting keywords and statistics".

To view extended statistics (competitor anchors), click on a non-empty cell in the Solomono statistics column.

Determining the correctness of word forms
The program supports determining the correctness of word forms based on search suggestions.
In order to determine the correctness of word forms for existing key phrases, click on the button with the hand icon in the group of buttons "Collecting keywords and statistics".

Attention: the information provided by this function is only indicative and does not guarantee the correctness of the definition. This function can be useful when cleaning up "garbage" from a large array of phrases of high and medium popularity as a primary "quality filter".
KEI
The program allows you to collect data from the KEI group from three popular search engines: Yandex, Google, Mail. The components of the KEI group mean competition (the number of documents in the search results on request), the number of main pages in the search results and the number of exact occurrences of a given key phrase in the titles of pages located in the search results.
The collection of the components of the KEI group is carried out through the drop-down button with the inscription KEI in the group of buttons "Collecting keywords and statistics".

You can customize the visibility of the search results, which the program will consider when collecting the components of the KEI group, the query format (word or "word"), as well as formulas for calculating KEI values and some other settings in "Settings - KEI".

In order to view extended statistics on entries in page titles, click on a non-empty cell in this column.

By default, the collection and recording of snippets are disabled in the settings. information about them can take up a lot of space. If you want to receive these statistics, then enable the option "Record snippets for Yandex and Google search engines" v "Settings - KEI".
You can upload information about headers and snippets to an external file (CSV or XLSX) through the item "Export search results data" in the drop-down menu of the KEI button.
Identifying relevant pages
The program allows you to determine the relevant pages of the site for the given key phrases in the search engines Yandex and Google.
"Add" in the button group "Operations with a table"
Use the buttons in the status bar to set the regional settings.
To start the analysis of relevant pages, use the button "Yandex" or "Google" in the button group.

By default, the most relevant page is selected as the relevant page, i.e. page at the first position of search results for a request. You can change the page manually. To do this, you need to click on the cell, the value of which you want to change, and select another page from the proposed ones, or enter the URL manually.

If necessary, you can register any address in several cells at once with one click. To do this, call the context menu in the cell with the address and select the item "Apply to all selected lines" or "Apply to All Filtered Rows".
We remind you that the text colored in dark blue allows you to switch to the browser while holding down the CTRL key.
Removing positions
The program allows you to determine the position of the site for the given key phrases in the search engines Yandex and Google.
You can add words to the data table manually via the button "Add" in the button group "Operations with a table" or copy from other tabs.
Use the buttons in the status bar to set the regional settings.
"Yandex" or "Google" in the button group "Relevant pages, positions and site analysis".

You can configure the visibility scope within which the program will search for a given site in "Settings - Parsing - Search results"... Since the removal of positions is associated with the alternate viewing of search results from the beginning to the depths, you may find the option useful "Number of requested results in search results", where you can set the value 50 to reduce the number of queries made to the search engine.
The program supports viewing the history of positions. You can see the relative position change since the last shot. To do this, you need to "Settings - Parsing - General" select collection mode "Marked Lines" or "Blank or Marked Lines", and then mark the phrases for which you would like to update positions and start the collection.

The relative change appears on the right side of the cell. If the dynamics are positive (the site has risen in the search results), then the number will be colored green (for example, 10). If the dynamics are negative (the site has dropped in search results), then the number will be colored red (for example, -4).
In addition, you can observe the overall dynamics both in the form of a graph and in a tabular form.

If necessary, you can export the position report into Microsoft Excel format. The unload button is located next to the item collection button.

You can add words to the data table manually via the button "Add" in the button group "Operations with a table" or copy from other tabs.

To start collecting positions, use the button "Collecting recommendations from Yandex PS" in the button group "Relevant pages, positions and site analysis"... You will be prompted to specify the parts of the URLs of the pages (sections of the site) that you would not like to see in the recommendations. For example, if on the site the addresses of the catalog of goods are of the form http://site.ru/shop/items/22, and you are not going to link to the product pages of this section, you can write the exception as: shop / items /.
The result of the work will be filled in the fields " Acceptor"and at the second level of lines.








